
Introduction
Ask any executive or practitioner what their biggest pain in cybersecurity is, and the answer you'll hear most often is something like "noise," "false positives," or "It's hard to know what actually matters." Security scanners, of varying types, tend to surface a ton of alerts that aren't trustworthy, bury you in unconnected data points, or suggest fixes that aren't practical. In this article, we outline where false positives come from and how we reduce them.
The root cause of false positives
Most SAST false positives come from the same blind spot. Traditional scanners pattern-match code without knowing how the application runs when in production. Without the application's runtime context, scanners will flag benign flaws in software as high-priority vulnerabilities that require a security analyst or engineer to chase down and validate. Add that up across thousands and thousands of vulnerabilities, and the time wasted on false positives becomes a drain on a security program.
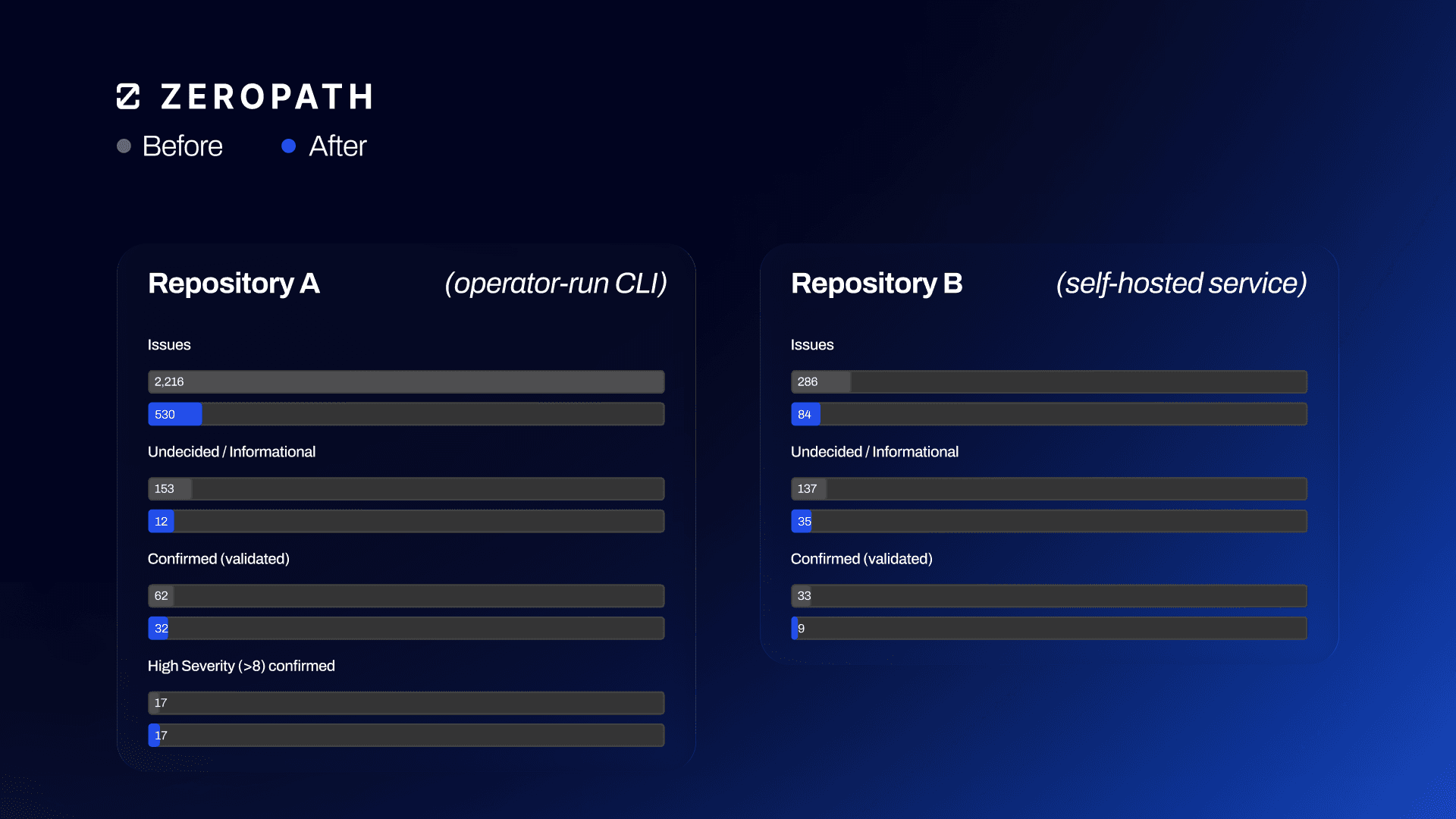
We've tested this ourselves by scanning the same commit in two repositories — one with and one without repository context (a few plain-language facts about each app's deployment model, trust boundaries, and authentication). In one repository, the scan results fell from 2,216 to 530, with no high-severity bugs missing.
Why does SAST flag issues that aren't actually exploitable?
Because pattern-based SAST can't capture nuances of a production deployment, such as trust boundaries or authentication, intended behavior and unreachable code can look identical to real bugs. A function that runs arbitrary shell input is a textbook vulnerability in a public web service. In an operator-run build tool, it is the point of the product: whoever supplies the input already controls the machine. Without that context, a scanner reports both the same way and buries the issues that matter. ZeroPath's SAST engine casts a wide net first, then decides which issues are real based on your application's trust model.
How do you cut SAST false positives without losing real bugs?
You can reduce false positives by providing your security scanner with declarative facts about your codebase that enable it to validate issue exploitability. For example, that a service is operator-run rather than internet-facing, that certain inputs come from admin-authored configuration, or that a web UI offers no session guarantees.
During validation, ZeroPath uses repository context facts to ask, for each finding, whether a real attacker could reach the vulnerability. We suppress findings that are intended behavior or unreachable, and only surface findings with a genuine path to exploitation. Each choice the scanner makes is explained, so you can see why a finding survived or was dropped. By providing repo context, you're increasing accuracy without losing fidelity.
What's the difference between repository context and custom rules?
Repository context is declarative, meaning it consists of facts that are already true about your stack, such as "this input is admin-only" or "this endpoint is internal," used to refine and validate existing findings and reduce false positives. Custom rules are imperative policies that must always hold, such as "no raw SQL outside the data layer," that create new findings when violated.
Context lowers noise while rules add coverage for organization-specific requirements. ZeroPath's policy engine drives the rules side, while repository context drives validation; together, they work best. Reaching for a rule when you need context (or the reverse) is a common mistake, so ZeroPath documents the boundary between repository context and custom rules, along with an overview of repository context.
Real-world scanning comparison
We recently scanned an organization's application security posture with and without the added context of two very different repositories, and rescanned each at the same commit. The first is an operator-run command-line build tool — software a person runs locally rather than a network service — whose inputs come from the configuration the operator writes.
| Repository A (operator-run CLI) | Before | After |
|---|---|---|
| Issues | 2,216 | 530 |
| Undecided / informational | 154 | 12 |
| Confirmed (validated) | 62 | 32 |
| High-severity (≥8) confirmed | 17 | 17 |
The suppressed findings were command execution, which is the tool's intended, operator-controlled behavior. Not one high-severity bug was lost.
The second repository is a self-hosted web service whose data connectors and rules are admin-authored and whose web UI has weak authentication guarantees.
| Repository B (self-hosted web service) | Before | After |
|---|---|---|
| Issues | 286 | 84 |
| Undecided / informational | 137 | 35 |
| Confirmed (validated) | 33 | 9 |
Here, ZeroPath dropped configuration-only injection that no external attacker can reach and kept the genuinely reachable web-facing issues: weak web-UI authentication, token handling, and injection fed by externally ingested data. Those are business-logic bugs, the kind that depend on knowing who controls what.
Does adding context just hide findings or lower my severity numbers?
No — using context to improve finding accuracy doesn't just hide findings, though it does intentionally make the totals smaller. Confirmed findings fell from 62 to 32 on the first repository and from 33 to 9 on the second, while average severity remained flat or slightly lower. That is the intent: the removed findings were not exploitable in each app's real trust model, so cutting them raises precision without hiding real risk. On the build tool, all 17 high-severity findings survived the change. For an enterprise security team, a short queue that is exploitable by default is worth far more than a long one padded with intended behavior.
Key takeaways
- Most SAST false positives come from missing deployment and business context, not weak detection.
- Repository context is declarative (facts that validate findings), while custom rules are imperative (policies that create findings). They are complementary.
- Repository context cut issues by 71-76% and undecided findings by 74-92% across two repositories.
- Severity-aware validation kept every high-severity bug on the build tool while removing non-exploitable noise.
- Context is what lets SAST reason about business-logic and trust-model bugs rather than just matching patterns.
See it on your own code
Add repository context to your repositories, then rescan the same commit to see which findings survive. Get a demo of ZeroPath.



