See the Difference
Traditional SAST floods you with alerts. AI SAST shows what actually matters - real vulnerabilities with contextual understanding and actionable fixes.
SCA Without AI
"You have 500 vulnerable dependencies!"
SCA With AI
"You have 12 exploitable vulnerabilities in code paths you actually use"
IaC Without AI
"223 misconfigurations found!"
IaC With AI
"7 critical misconfigurations that expose production data"
SAST Without AI
"Potential SQL injection on line 1,847"
SAST With AI
"No risk. Input is pre-validated and query is parameterized"
AI AppSec begins analyzing immediately:
Within seconds, get:
fewer false positives than traditional SAST
PR scans without sacrificing depth
companies trusting AI-powered security
scans monthly continuously improving our AI
AI reviews every commit, understanding code intent and security implications
Identifies security vulnerabilities, from OWASP Top 10 to business logic flaws
Provides clear explanations with proof-of-concept and impact analysis
Generates secure patches that match your coding standards
Traditional SAST floods you with alerts. AI SAST shows what actually matters - real vulnerabilities with contextual understanding and actionable fixes.
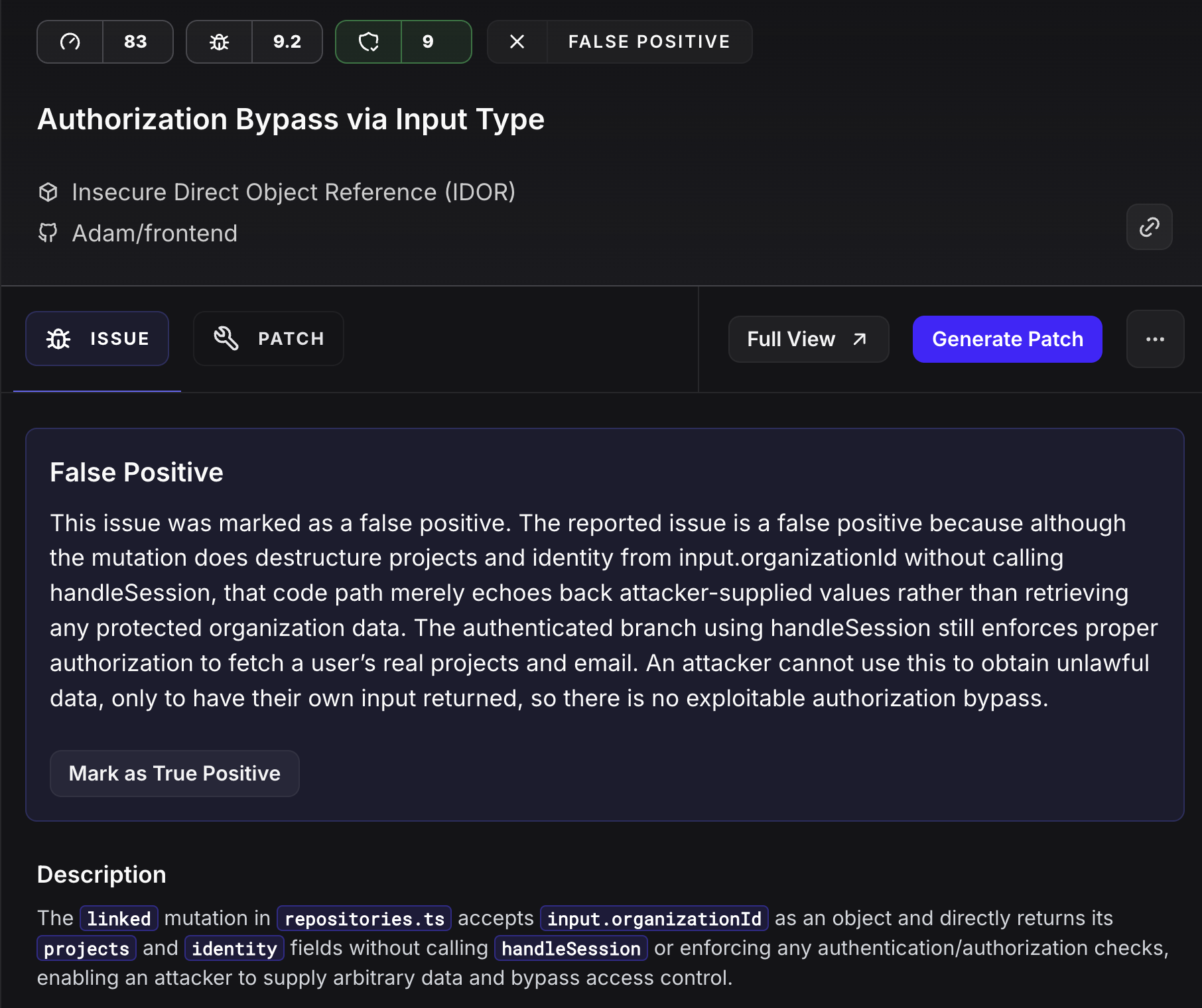
Our AI doesn't just pattern match - it understands your entire security context. It knows when a query is safe because of upstream validation, framework protections, or proper parameterization.
Example: Traditional SAST sees string concatenation and screams "SQL injection!" Our AI sees the JWT validation, role checks, and parameterized execution that make it safe.
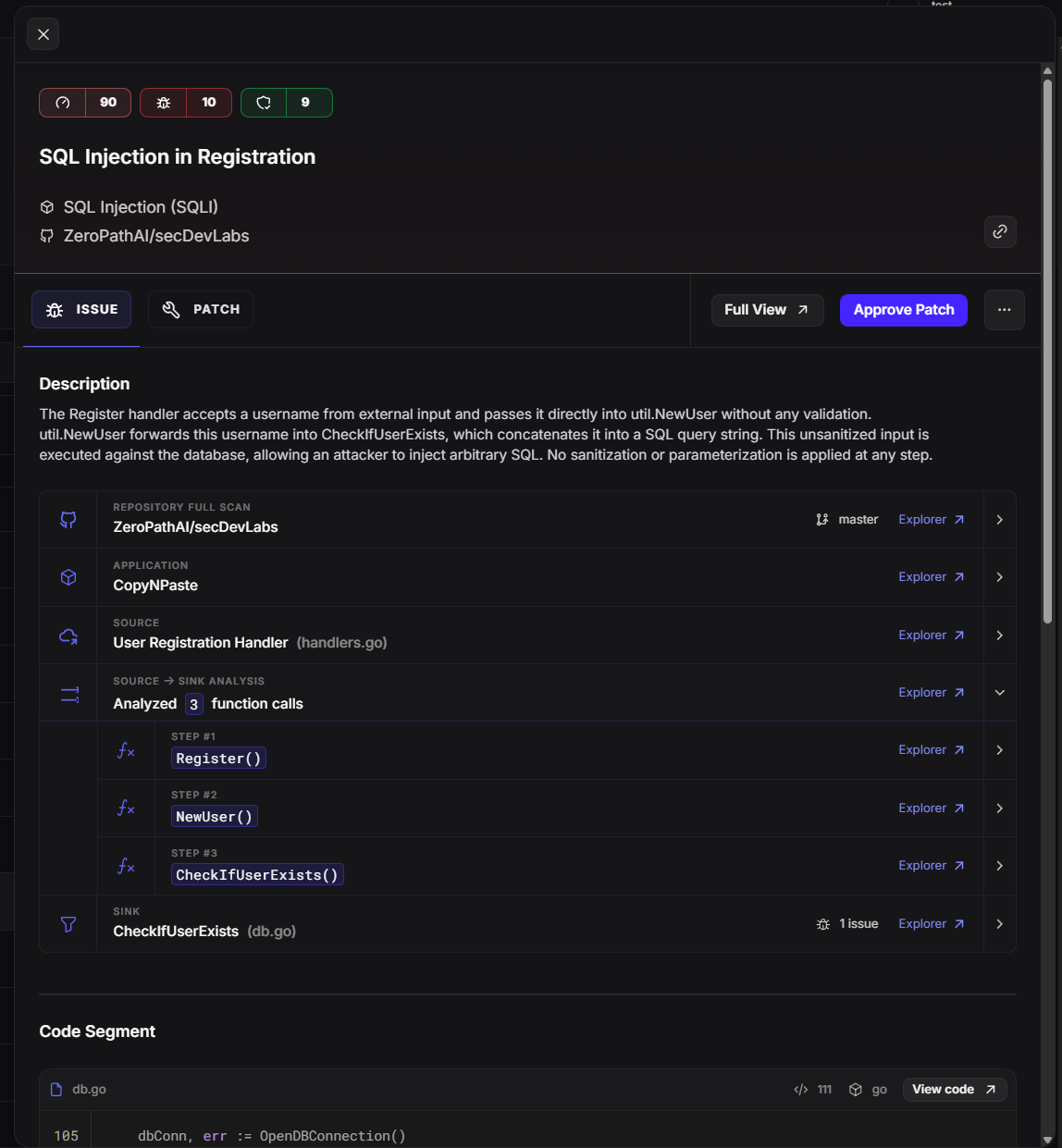
One-click patches that actually work in your codebase
Matches your coding style and patterns perfectly
Preserves functionality while fixing security issues
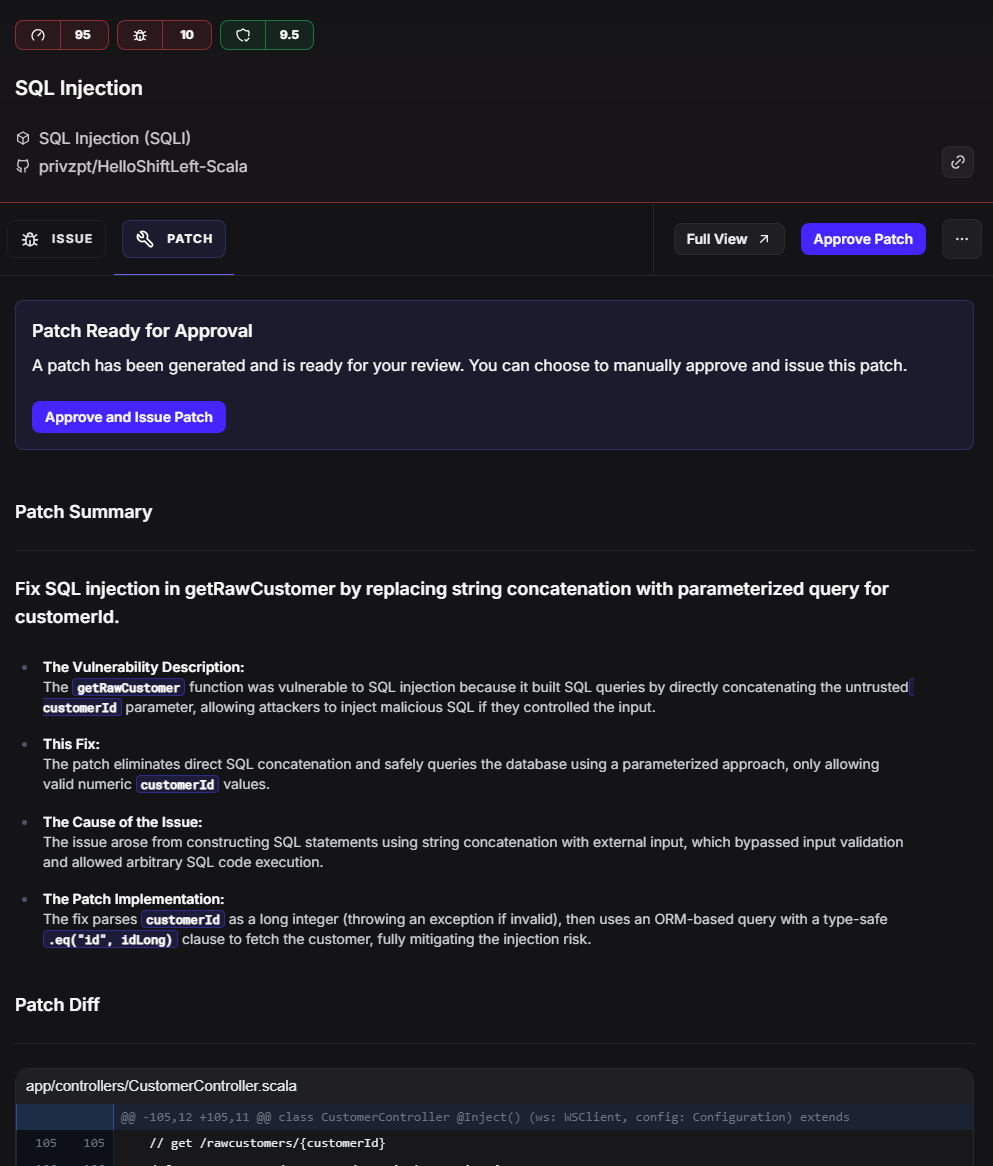
That's the typical reduction when ZeroPath's AI processes your existing SAST findings.
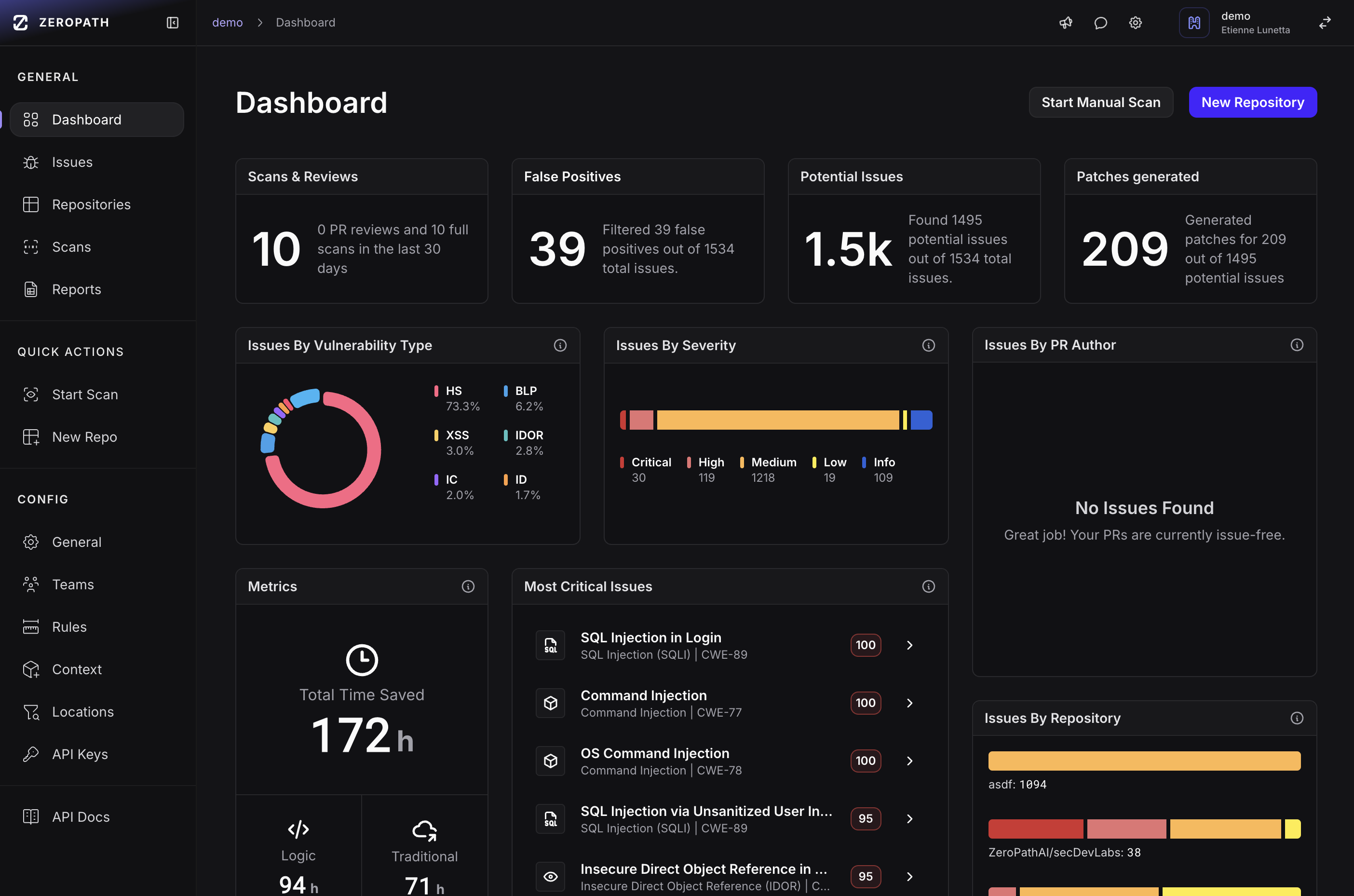
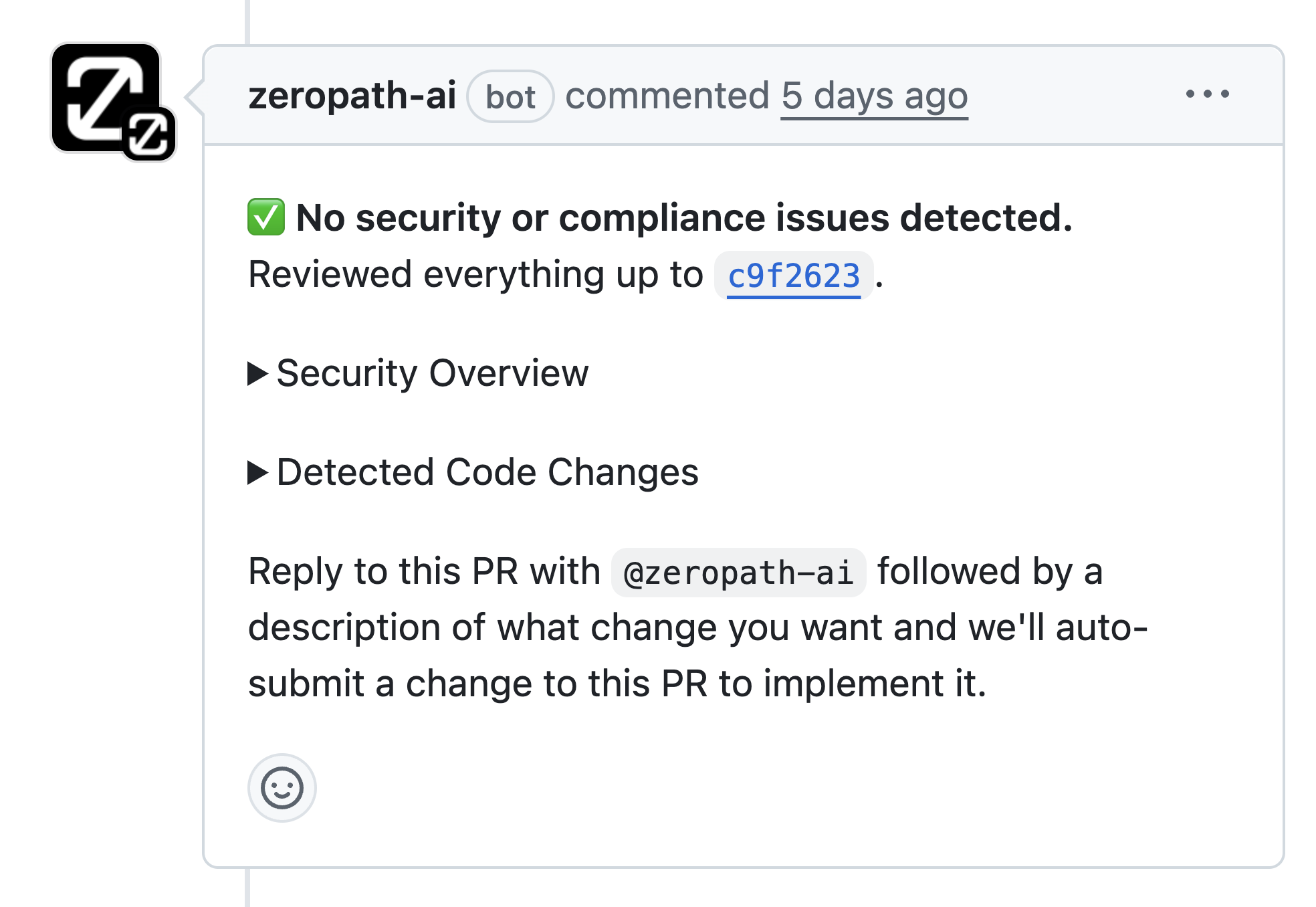
Security feedback right in the PR. Developers fix issues before they merge, not months later in production.
Get explanations in plain English about vulnerabilities and fixes
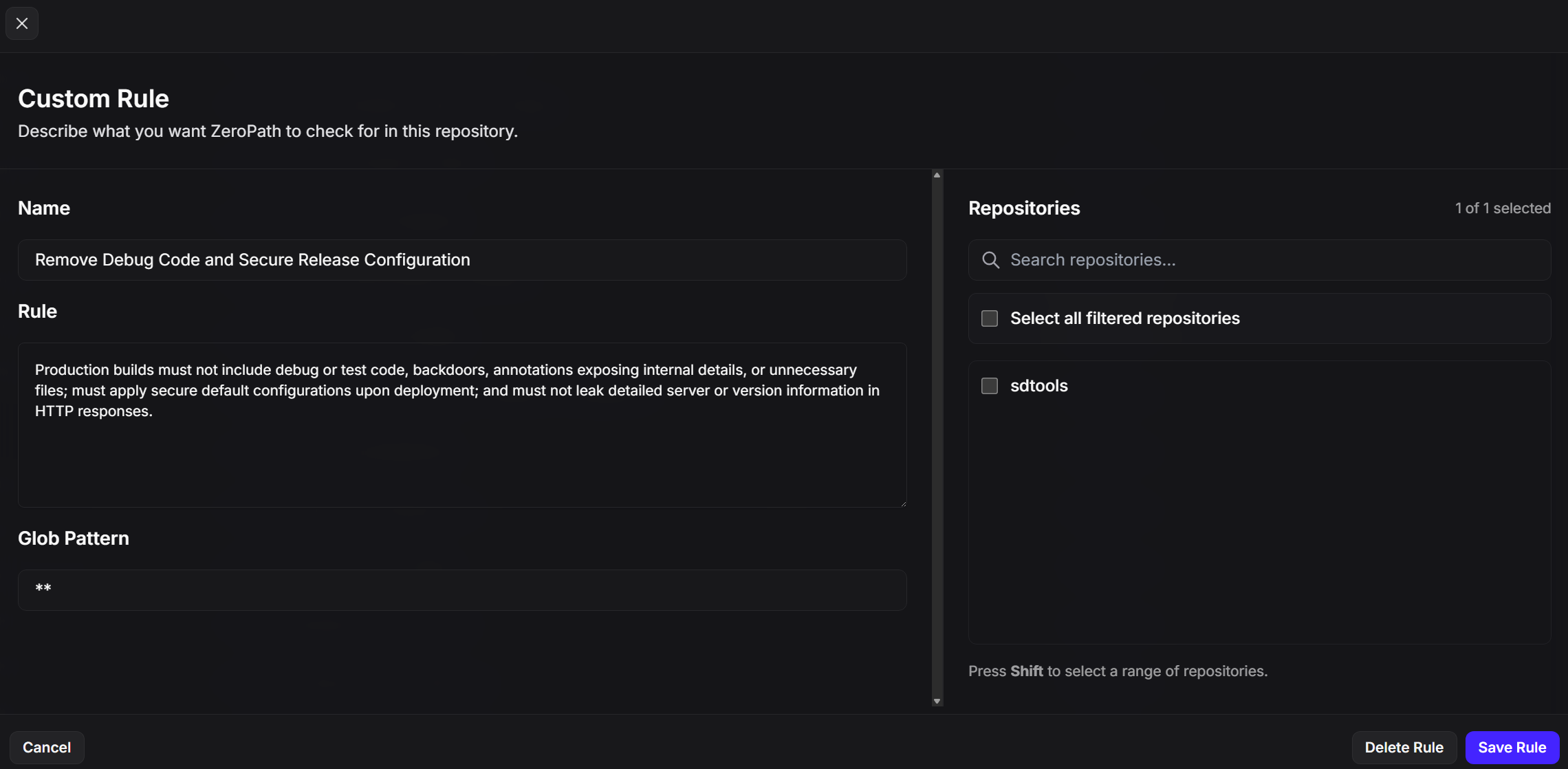
Create security policies without regex knowledge
Build security expertise through intelligent feedback
Link your VCS with one-click OAuth integration
30 seconds
See real vulnerabilities, not false positives
30 seconds
One-click patches that respect your codebase
Instant
Automatically map all API endpoints across REST, GraphQL, gRPC, and WebSockets
Trace data flows from endpoint to database, understanding authentication and authorization
Identify OWASP API Top 10 vulnerabilities and business logic flaws
Generate fixes and update API documentation automatically
Real context SAST detects SQLi, XSS, SSRF, broken authN/authZ, and business logic issues
AI scores issues based on CVSS 4.0, considering entire context to prevent wasted developer time
Autopatch generates a secure diff in your branch that matches your coding standards
Fail-safe CI blocks until vulnerability is verified as fixed (with audited break-glass option)
SAST, SCA, secret, and IaC scans map each finding to exact control clauses
Dashboards show MTTR, SLA breaches, and risk trends by business unit
Schedule evidence packs with signed SBOMs and fix verification records
Generate audit-ready attestations with cryptographic proof of compliance
Native CI/CD hooks for GitHub, GitLab CI, Azure, Bitbucket Pipelines and any generic runner
Context-aware scanning combines SAST, SCA, secrets, IaC, and policy checks in under 60 seconds
One-click pull request patches with Auto AppSec Mode for hands-free remediation
Policy-driven approvals ensure security without blocking legitimate releases
Analyzes only changed code paths, completing in under 60 seconds
Deep weekend scans with Auto-AppSec mode for comprehensive coverage
Native integration with Slack, Teams, Jira, and Linear
Analytics dashboard tracks security velocity metrics
Consolidate SAST, SCA, secrets, IaC, custom policies, PR reviews, risk management, and autofix into one platform
AI-driven analytics surface critical trends and predict risk trajectories
Policy engine enforces security standards across all teams and repositories
Executive dashboards and compliance reports generated on-demand
LLM-driven analysis across SAST, SCA, secrets & IaC in one pass
Find PII leaks, auth flaws, and payment logic vulnerabilities
Auto-map to PCI DSS, SOX, GLBA controls with evidence collection
AI-generated fixes that match your coding standards
Auto-align every finding to ISO 27001, SOC 2, PCI-DSS, NIST controls
Real-time dashboards show control coverage and compliance gaps
Automated collection with immutable logs and signed attestations
One-click reports for auditors, scheduled syncs to GRC platforms
Comprehensive analysis of healthcare applications and APIs
Find PHI exposure, access control issues, and encryption gaps
Auto-map to HIPAA technical safeguards and generate evidence
AI-generated fixes that maintain healthcare data standards
Spin up isolated workspaces for each client in minutes
Unified SAST, SCA, secrets, IaC, custom policies, PR reviews, risk management, and autofix across all repos
Multi-tenant console with granular RBAC and API automation
White-label dashboards and automated compliance evidence
AI-aware detections + deep-flow analysis scan every push in < 60s
Risk-rank by exploitability, data sensitivity & business logic
LLM generates a ready-to-merge patch and unit test
CI reruns the scan to guarantee the vulnerability is gone
Consolidate all AppSec tools into a single platform
AI-driven analysis with reachability and exploitability scoring
Focus on material risks using CVSS 4.0 and business context
Executive dashboards and compliance evidence on-demand
Map your entire dependency tree including transitive dependencies
Call-graph analysis identifies which code paths are actually reachable
Focus only on exploitable vulnerabilities in your execution paths
AI-suggested upgrades that won't break your application